

|
|

|
Промышленный лизинг
Методички
этого нам потребуется распределение относительных частот нашей случайной переменной. В качестве примера возьмем следующее распределение относительных частот доходов по активу. В этом случае высота столбца, где доходность составила данное значение, соответствует проценту от всех наблюдений. Также сумма всех процентов для каждого типа наблюдения должна составлять 100 или 1 в зависимости от представления частностей в процентах или долях единицы (рис. 8.12). Это распределение относительных частот относится к дневным доходам по индексу FTSE 100 с 1984 по 1992 гг. Используя это распределение, мы можем построить кумулятивное распределение относительных частот, изображенное на рис. 8.13. Заметим, что в случае кумулятивного распределения относительных частот вертикальная ось размечена в интервале до единицы, представляя тем самым эмпирическую вероятность, относящуюся к соответствующему значению, расположенному на горизонтальной оси. На горизонтальной оси же в свою очередь отмечен уровень дохода. 0.12 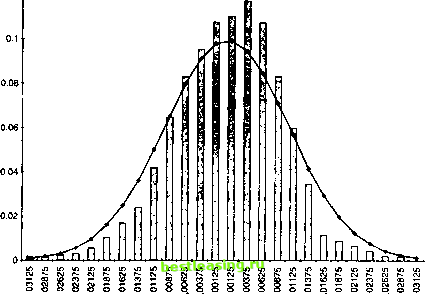 f ? i ? f f i f i f ? ? i f i ? i f f ? i f ?* ? ?* ? Рис. 8.12 Рис. 8.13 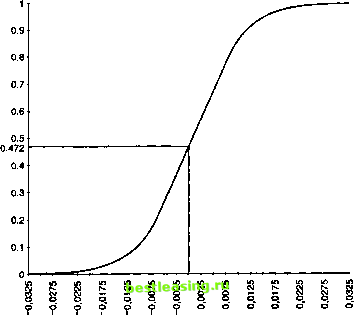 Этап 2: пмптаипя входных переменных Второй этап заключается в моделировании поведения входных случайных переменных. Для этого необходимо сгенерировать достаточно большое количество равномерно распределенных случайных чисел в интервале от 0 до 1. Затем каждое случайное число откладывается по вертикальной оси кумулятивной плотности, а соответствующее значение случайной переменной находится по горизонтальной оси. Эти значения являются входными для данной модели. Так как кумулятивное распределение относительных частот отражает и величину основной переменной (доход в нашем случае), и эмпирическое распределение вероятностей, значения на горизонтальной оси представляют собой случайные наблюдения основной переменной с эмпирическим распределением вероятностей, которое сходно с распределением подлинных данных. Для иллюстрации этого представим, что сгенерировано случайное число 0,472, располагаемое на вертикальной оси. Двигаясь от него горизонтально по направлению к функции ку- мулятивной плотности, а от точки пересечения с ней - перпендикулярно к оси абсцисс, получим доход, выбранный случайным образом. Если наши данные относятся к дневным доходам по активу, результатом является случайно сгенерированный однодневный доход, определенный исходя из распределения вероятностей, которое сходно с первоначальным эмпирическим распределением. Конечно, благодаря современным компьютерным программам подобные процедуры, выполняемые вручную , заменяются компьютеризированными процессами, но в сущности они аналогичны описанным. Интересно заметить, что числа из генератора случайных чисел, находящиеся в интервале от 0,4 до 0,6, дают результат в диапазоне от -0,25 до 0,25, тогда как случайные числа от 0,7 до 0,9 дают результат от 0,52 до 1,28. Таким образом, крутизна огивы в середине - причина более плотного расположения результатов, тогда как пологость граничных ветвей кривой - причина более разбросанных результатов (в точности то, что и описывает функция вероятности). Некоторые читатели могут спросить, почему мы прибегаем к такому процессу, когда, используя допущение нормальности, можно получить такой же результат. Ответить можно так. Использование нормального распределения обоснованно только в том случае, если доходы независимы. Однако, если существует корреляция в рядах данных доходов, процедура не приведет к обоснованным результатам. Существует же свидетельство того, что корреляция в рядах валют, процентных ставок и индексов ценных бумаг присутствует. Этап 3: моаелпрованпе основной переменной Третий этап - объединение входных значений в соответствии с логикой системы. Система описывает, каким образом каждое индивидуальное входное значение участвует в получении результата на выходе, которым в нашем примере является оценка будущего значения индекса FTSE 100. Сейчас мы прервемся на некоторое время, чтобы определить, что мы вообще понимаем под моделированием. В контексте методологии Монте-Карло мы получаем результат всего моделирования (simulation) (которое со- 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 [ 136 ] 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 |