

|
|

|
Промышленный лизинг
Методички
Gaussian mixture models are a probabilistic variant of K-means. The name comes from the Gaussian distribution, a probability distribution often assumed for high-dimensional problems. The Gaussian distribution generalizes the normal distribution to more than one variable. As before, the algorithm starts by choosing K seeds. This time, however, the seeds are considered to be the means of Gaussian distributions. The algorithm proceeds by iterating over two steps called the estimation step and the maximization step. The estimation step calculates the responsibility that each Gaussian has for each data point (see Figure 11.8). Each Gaussian has strong responsibility for points that are close to its mean and weak responsibility for points that are distant. The responsibilities are be used as weights in the next step. In the maximization step, a new centroid is calculated for each cluster taking into account the newly calculated responsibilities. The centroid for a given Gaussian is calculated by averaging all the points weighted by the responsibilities for that Gaussian, as illustrated in Figure 11.9. 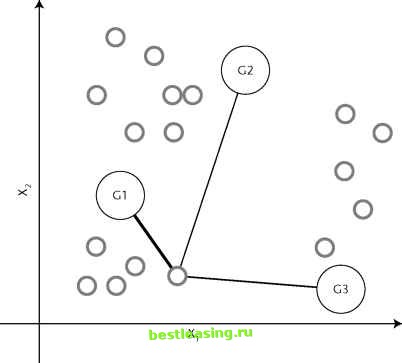 Figure 11.8 In the estimation step, each Gaussian is assigned some responsibility for each point. Thicker lines indicate greater responsibility. These steps are repeated until the Gaussians no longer move. The Gaussians themselves can change in shape as well as move. However, each Gaussian is constrained, so if it shows a very high responsibility for points close to its mean, then there is a sharp drop off in responsibilities. If the Gaussian covers a larger range of values, then it has smaller responsibilities for nearby points. Since the distribution must always integrate to one, Gaussians always gets weaker as they get bigger. The reason this is called a mixture model is that the probability at each data point is the sum of a mixture of several distributions. At the end of the process, each point is tied to the various clusters with higher or lower probability. This is sometimes called soft clustering, because points are not uniquely identified with a single cluster. One consequence of this method is that some points may have high probabilities of being in more than one cluster. Other points may have only very low probabilities of being in any cluster. Each point can be assigned to the cluster where its probability is highest, turning this soft clustering into hard clustering. 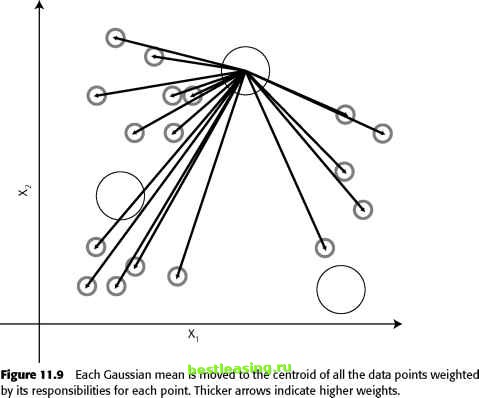 Agglomerative Clustering The K-means approach to clustering starts out with a fixed number of clusters and allocates all records into exactly that number of clusters. Another class of methods works by agglomeration. These methods start out with each data point forming its own cluster and gradually merge them into larger and larger clusters until all points have been gathered together into one big cluster. Toward the beginning of the process, the clusters are very small and very pure-the members of each cluster are few and closely related. Towards the end of the process, the clusters are large and not as well defined. The entire history is preserved making it possible to choose the level of clustering that works best for a given application. An Agglomerative Clustering Algorithm The first step is to create a similarity matrix. The similarity matrix is a table of all the pair-wise distances or degrees of similarity between clusters. Initially, the similarity matrix contains the pair-wise distance between individual pairs of records. As discussed earlier, there are many measures of similarity between records, including the Euclidean distance, the angle between vectors, and the ratio of matching to nonmatching categorical fields. The issues raised by the choice of distance measures are exactly the same as those previously discussed in relation to the K-means approach. It might seem that with N initial clusters for N data points, N2 measurement calculations are required to create the distance table. If the similarity measure is a true distance metric, only half that is needed because all true distance metrics follow the rule that Distance(X,Y) = Distance(Y,X). In the vocabulary of mathematics, the similarity matrix is lower triangular. The next step is to find the smallest value in the similarity matrix. This identifies the two clusters that are most similar to one another. Merge these two clusters into a new one and update the similarity matrix by replacing the two rows that described the parent cluster with a new row that describes the distance between the merged cluster and the remaining clusters. There are now N - 1 clusters and N - 1 rows in the similarity matrix. Repeat the merge step N - 1 times, so all records belong to the same large cluster. Each iteration remembers which clusters were merged and the distance between them. This information is used to decide which level of clustering to make use of. Distance between Clusters A bit more needs to be said about how to measure distance between clusters. On the first trip through the merge step, the clusters consist of single records so the distance between clusters is the same as the distance between records, a subject that has already been covered in perhaps too much detail. Second and 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 [ 130 ] 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 |