

|
|

|
Промышленный лизинг
Методички
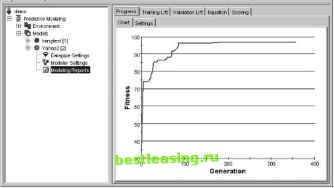 Figure 13.7 The Genalytics system shows the progress of the training and how the fitness function improves with each generation. Beyond the Simple Algorithm Researchers have been pushing the bounds on genetic algorithms in several directions. Some of these enhancements are refinements to the basic algorithm; others modify the algorithm to provide a better model of genetic activity in the natural world. This work is often performed under the rubric of machine learning, an area of current artificial intelligence research that aims to enable computers to learn in ways analogous to humans. Companies such as Genalytics are starting to apply these evolutionary techniques to marketing. The simple genetic algorithm previously described has room for improvement in several areas. One of the inefficiencies in the algorithm is the fact that entire populations are replaced from one generation to the next. This is a gross oversimplification of what happens in nature. Instead of replacing an entire population, some researchers have worked with overlapping populations that can grow in size. They have introduced the notion of crowding to determine which existing members should be targeted for replacement. When applied naively, this tends to result in very fast convergence, often to suboptimal solutions, because all the less fit genomes are replaced before they have an opportunity to reproduce-and the less fit genomes sometimes have something to offer. To get around this, the targets for replacement often come from subsets of the population that exhibit high degrees of similarity. The issue of overly fast convergence is actually a problem for the simple genetic algorithm because the goal of finding the globally optimal solution is easily confused by locally optimal solutions. Overly fast convergence often suggests that the search is being limited. To get around this, the various probabilities for crossover and mutation are often set high initially, then slowly decreased from one generation to the next. Or, an initial population is allowed to grow before shrinking in size as the fitness becomes more consistent across the population. The genomes discussed so far consist of only a single strand of genes. Didnt we learn back in high school that DNA consists of two intertwining strands in a helix structure? And what happened to those other concepts buried back in this high-school past, such as recessive and dominant genes? The genetics used so far is based on the simplest chromosomes found in nature, single-stranded, or haploid chromosomes. These tend to be found in uncomplicated, single-cell organisms. In more complex organisms, the chromosomes are two-stranded, or diploid, as in our own DNA. The algorithmic characteristics of diploid chromosomes are much the same as haploid chromosomes, since diploid chromosomes can be treated as two chromosomes tied together. The actual algorithm proceeds in much the same way: Selection, crossover, and mutation are the same. The difference is that now there are two alleles for each gene (two possible values) instead of one. When they match, there is no problem. When they do not, which does the fitness function use? In the language of genetics, this is asking which of the alleles is expressed. For instance, when an allele for blue eyes pairs up with an allele for brown eyes, the brown eyes win ; that is, they are expressed instead of the blue eyes. (Actually, eye color is a bit more complicated than this simple example, but this is useful for explanatory purposes.) Researchers have solved this problem by including information about dominance in the alleles themselves. The details of this mechanism are beyond the scope of this book. The interested reader is referred to Goldbergs classic book Genetic Algorithms in Search, Optimization, and Machine Learning (1989, Addison-Wesley, ISBN 0201157675) Why we should care about diploid structures? Geneticists have long wondered why two-stranded chromosomes predominate in nature, when single-stranded ones are simpler. They believe that the two-stranded structure allows an organism to remember a gene that was useful in another environment, but has become less useful in the current environment. In terms of GA, this suggests that these are useful in cases where the environment-or fitness function-is changing over time. In the real world, this may prove to be quite useful. An example of a changing fitness function would be a function that tried to determine the price of bonds over time. The goodness of a given bond price depends on factors not under control of the algorithm, such as the rate of inflation. The fitness function can take this into account by changing over time to incorporate estimates of inflation. Lessons Learned Genetic algorithms are a very powerful optimization technique. Optimization is not at the heart of data mining, but it can solve interesting and important problems. In fact, some data mining algorithms, such as neural networks, depend on optimization under the hood. The key to the power of genetic algorithms is that they depend on only two things. First is the genome and the second the fitness function. The fitness function makes sense of the genome, by producing a value from what looks like a random set of bits. The genome encodes the problem; often it consists of a set of weights on some equation. Genetic algorithms work on a wide variety of fitness functions, making it possible to encode many different types of problems that are not easily handled by other means. The process of evolution starts with a random population and then applies three transformation steps. The first is selection, which means that more fit genomes survive from one generation to another. This corresponds to natural selection. The second is crossover, where two genomes swap pieces and is analogous to a similar natural process. The third is mutation, where some values are changed randomly. Mutations are usually quite rare both in nature and in genetic algorithms. The application of these three processes produces a new generation, whose average fitness should be greater than the original. As more and more generations are created, the population moves to an optimal solution. These processes have a theoretical foundation, based on schemata. This theory explains how genetic algorithms move toward a solution. Genetic algorithms have been applied to practical problems, often to resource optimization problems. However, they can even be used for predictive modeling and classification, as explained in the case study on classifying comments made to an airline. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 [ 156 ] 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 |