

|
|

|
Промышленный лизинг
Методички
BACKGROUND ON PARALLEL TECHNOLOGY Parallel technology is the key to scalable hardware, and it comes in two flavors: symmetric multiprocessing systems (SMPs) and massively parallel processing systems (MPPs), both of which are shown in the following figure. An SMP machine is centered on a bus, a special network present in all computers that connects processing units to memory and disk drives. The bus acts as a central communication device, so SMP systems are sometimes called shared everything. Every processing unit can access all the memory and all the disk drives. This form of parallelism is quite popular because an SMP box supports the same applications as uniprocessor boxes-and some applications can take advantage of additional hardware with minimal changes to code. However, SMP technology has its limitations because it places a heavy burden on the central bus, which becomes saturated as the processing load increases. Contention for the central bus is often what limits the performance of SMPs. They tend to work well when they have fewer than 10 to 20 processing units. MPPs, on the other hand, behave like separate computers connected by a very high-speed network, sometimes called a switch. Each processing unit has its own memory and its own disk storage. Some nodes may be specialized for processing and have minimal disk storage, and others may be specialized for storage and have lots of disk capacity. The bus connecting the processing unit to memory and disk drives never gets saturated. However, one drawback is that some memory and some disk drives are now local and some are remote-a distinction that can make MPPs harder to program. Programs designed for one processor can always run on one processor in an MPP-but they require modifications to take advantage of all the hardware. MPPs are truly scalable so long as the network connecting the processors can supply more bandwidth, and faster networks are generally easier to design than faster buses. There are MPP-based computers with thousands of nodes and thousands of disks. Both SMPs and MPPs have their advantages. Recognizing this, the vendors of these computers are making them more similar. SMP vendors are connecting their SMP computers together in clusters that start to resemble MPP boxes. At the same time, MPP vendors are replacing their single-processing units with SMP units, creating a very similar architecture. However, regardless of how powerful the hardware is, software needs to be designed to take advantage of these machines. Fortunately, the largest database vendors have invested years of research into enabling their products to do so. (continued) BACKGROUND ON PARALLEL TECHNOLOGY (continued) Uniprocessor A simple computer follows the architecture laid out by Von Neumann. A processing unit communicates to memory and disk over a local bus. (Memory stores both data and the executable program.) The speed of the processor, bus, and memory limits performance and scalability.  The symmetric multiprocessor (SMP) has a shared-everything architecture. It expands the capabilities of the bus to support multiple processors, more memory, and a larger disk. The capacity of the bus limits performance and scalability. SMP architectures usually max out with fewer than 20 processing units. 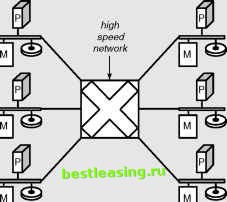 The massively parallel processor (MMP) has a shared-nothing architecture. It introduces a high-speed network (also called a switch) that connects independent processor/memory/disk components. MPP architectures are very scalable but fewer software packages can take advantage of all the hardware. Parallel computers build on the basic Von Neumann uniprocessor architecture. SMP and MPP systems are scalable because more processing units, disk drives, and memory can be added to the system. Data warehousing is a process for managing the decision-support system of record. A process is something that can adjust to users needs as they are clarified and change over time. A process can respond to changes in the business as needs change over time. The central repository itself is going to be a brittle, little-used system without the realization that as users learn about data and about the business, they are going to want changes and enhancements on the time scale of marketing (days and weeks) rather than on the time scale of IT (months). Metadata Repository We have already discussed metadata in the context of the data hierarchy. It can also be considered a component of the data warehouse. As such, the metadata repository is an often overlooked component of the data warehousing environment. The lowest level of metadata is the database schema, the physical layout of the data. When used correctly, though, metadata is much more. It answers questions posed by end users about the availability of data, gives them tools for browsing through the contents of the data warehouse, and gives everyone more confidence in the data. This confidence is the basis for new applications and an expanded user base. A good metadata system should include the following: The annotated logical data model. The annotations should explain the entities and attributes, including valid values. Mapping from the logical data model to the source systems. The physical schema. Mapping from the logical model to the physical schema. Common views and formulas for accessing the data. What is useful to one user may be useful to others. Load and update information. Security and access information. Interfaces for end users and developers, so they share the same description of the database. In any data warehousing environment, each of these pieces of information is available somewhere-in scripts written by the DBA, in email messages, in documentation, in the system tables in the database, and so on. A metadata repository makes this information available to the users, in a format they can readily understand. The key is giving users access so they feel comfortable with the data warehouse, with the data it contains, and with knowing how to use it. Data Marts Data warehouses do not actually do anything (except store and retrieve data effectively). Applications are needed to realize value, and these often take the form of data marts. A data mart is a specialized system that brings together the data needed for a department or related applications. Data marts are often used for reporting systems and slicing-and-dicing data. Such data marts often use OLAP technology, which is discussed later in this chapter. Another 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 [ 171 ] 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 |