

|
|

|
Промышленный лизинг
Методички
Before ignoring a column, though, it is important to understand why the values are so heavily skewed. What does this column tell us about the business? Perhaps few people ever buy automotive products because only a handful of the stores in question even sell them. Identifying customers as automotive-product-buyers, in this case, may not be useful. In other cases, an event might be rare for other reasons. The number of people who cancel their telephone service on any given day is negligible, but over time the numbers accumulate. So the cancellations need to be accumulated over a longer time period, such as a month, quarter, or year. Or, the number of people who collect porcelain dolls may be very rare in itself, but when combined with other fields, this might suggest an important segment of collectors. The rule of thumb is that, even if a column proves to be very informative, it is unlikely to be useful for data mining if it is almost-unary. That is, fully understanding the rows with different values does not yield actionable results. As a general rule of thumb, if 95 to 99 percent of the values in the column are identical, the column-in isolation-is likely to be useless without some work. For instance, if the column in question represents the target variable for a model, then stratified sampling can create a sample where the rare values are more highly populated. Another approach is to combine several such columns for creating derived variables that might prove to be valuable. As an example, some census fields are sparsely populated, such as those for particular occupations. However, combining some of these fields into a single field-such as high status occupation -can prove useful for modeling purposes. Columns with Unique Values At the other extreme are categorical columns that take on a different value for every single row-or almost every row. These columns identify each customer uniquely (or close enough), for example: Customer name Address Telephone number Customer ID Vehicle identification number These columns are also not very helpful. Why? They do not have predictive value, because they uniquely identify each row. Such variables cause overfitting. One caveat-which will be investigated later in this chapter. Sometimes these columns contain a wealth of information. Lurking inside telephone numbers and addresses is important geographical information. Customers first names give an indication of gender. Customer numbers may be sequentially assigned, telling us which customers are more recent-and hence show up as important variables in decision trees. These are cases where the important features (such as geography and customer recency) should be extracted from the fields as derived variables. However, data mining algorithms are not yet powerful enough to extract such information from values; data miners need to do the extraction. Columns Correlated with Target When a column is too highly correlated with the target column, it can mean that the column is just a synonym. Here are two examples: Account number is NULL may be synonymous with failure to respond to a marketing campaign. Only responders opened accounts and were assigned account numbers. Date of churn is not NULL is synonymous with having churned. Another danger is that the column reflects previous business practices. For instance, the data may show that all customers with call forwarding also have call waiting. This is a result of product bundling; call forwarding is sold in a product bundle that always includes call waiting. Or the data may show that almost all customers reside in the wealthiest areas, because this where customer acquisition campaigns in the past were targeted. This illustrates that data miners need to know historical business practices. Columns synonymous with the targets should be ignored. An easy way to find columns synonymous with the target is to build decision trees. The decision tree will choose one synonymous variable, which can then be ignored. If the decision tree tool lets you see alternative splits, then all such variables can be found at once. Model Roles in Modeling Columns contain data with data types. In addition, columns have roles with respect to the data mining algorithms. Three important roles are: Input columns. These are columns that are used as input into the model. Target column(s). This column or set of columns is only used when building predictive models. These are what is interesting, such as propensity to buy a particular product, likelihood to respond to an offer, or probability of remaining a customer. When building undirected models, there does not need to be a target. Ignored columns. These are columns that are not used. Different tools have different names for these roles. Figure 17.4 shows how a column is removed from consideration in Angoss Knowledge Studio. 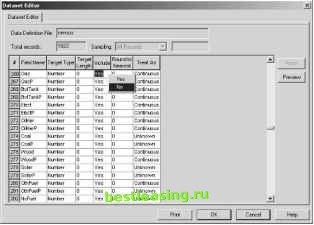 Figure 17.4 Angoss Knowledge Studio supports several model roles, such as ignoring a column when building a model. TIP Ignored columns play a very important role in clustering. Since ignored columns are not used to build the clusters, their distribution in the clusters can be very informative. By ignoring columns such as customer profitability or response flags, we can see how these ignored columns are distributed in the clusters. And we might just discover something very interesting about customer profit or responders. There are some more advanced roles as well, which are used under specific circumstances. Figure 17.5 shows the many model roles available in SAS Enterprise Miner. These model roles include: Identification column. These are columns that uniquely identify each row. In general, these columns are ignored for data mining purposes, but are important for scoring. Weight column. This is a column that specifies a weight to be applied to each row. This is a way of creating a weighted sample by including the weight in the data. Cost column. The cost column specifies a cost associated with a row. For instance, if we are building a customer retention model, then the cost might include an estimate of each customers value. Some tools can use this information to optimize the models that they are building. The additional model roles available in the tool are specific to SAS Enterprise Miners. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 [ 190 ] 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 |