

|
|

|
Промышленный лизинг
Методички
like. Data preparation is such an important topic that our colleague Dorian Pyle has written a book about it, Data Preparation for Data Mining (Morgan Kaufmann 1999), which should be on the bookshelf of every data miner. In this book, these issues are addressed in Chapter 17. Here are a few examples of such transformations. Capture Trends Most corporate data contains time series. Monthly snapshots of billing information, usage, contacts, and so on. Most data mining algorithms do not understand time series data. Signals such as three months of declining revenue cannot be spotted treating each months observation independently. It is up to the data miner to bring trend information to the surface by adding derived variables such as the ratio of spending in the most recent month to spending the month before for a short-term trend and the ratio of the most recent month to the same month a year ago for a long-term trend. Create Ratios and Other Combinations of Variables Trends are one example of bringing information to the surface by combining multiple variables. There are many others. Often, these additional fields are derived from the existing ones in ways that might be obvious to a knowledgeable analyst, but are unlikely to be considered by mere software. Typical examples include: obesity index = height2 / weight PE = price / earnings pop density = population / area rpm = revenue passengers * miles Adding fields that represent relationships considered important by experts in the field is a way of letting the mining process benefit from that expertise. Convert Counts to Proportions Many datasets contain counts or dollar values that are not particularly interesting in themselves because they vary according to some other value. Larger households spend more money on groceries than smaller households. They spend more money on produce, more money on meat, more money on packaged goods, more money on cleaning products, more money on everything. So comparing the dollar amount spent by different households in any one category, such as bakery, will only reveal that large households spend more. It is much more interesting to compare the proportion of each households spending that goes to each category. The value of converting counts to proportions can be seen by comparing two charts based on the NY State towns dataset. Figure 3.9 compares the count of houses with bad plumbing to the prevalence of heating with wood. A relationship is visible, but it is not strong. In Figure 3.10, where the count of houses with bad plumbing has been converted into the proportion of houses with bad plumbing, the relationship is much stronger. Towns where many houses have bad plumbing also have many houses heated by wood. Does this mean that wood smoke destroys plumbing? It is important to remember that the patterns that we find determine correlation, not causation. 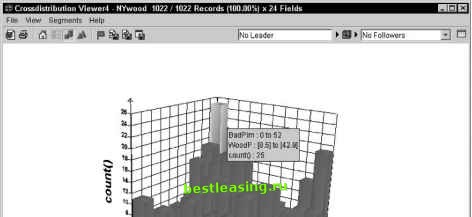  Figure 3.9 Chart comparing count of houses with bad plumbing to prevalence of heating with wood. 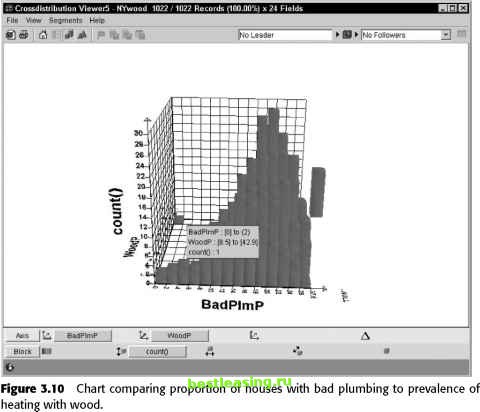 Step Seven: Build Models The details of this step vary from technique to technique and are described in the chapters devoted to each data mining method. In general terms, this is the step where most of the work of creating a model occurs. In directed data mining, the training set is used to generate an explanation of the independent or target variable in terms of the independent or input variables. This explanation may take the form of a neural network, a decision tree, a linkage graph, or some other representation of the relationship between the target and the other fields in the database. In undirected data mining, there is no target variable. The model finds relationships between records and expresses them as association rules or by assigning them to common clusters. Building models is the one step of the data mining process that has been truly automated by modern data mining software. For that reason, it takes up relatively little of the time in a data mining project. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 [ 33 ] 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 |