

|
|

|
Промышленный лизинг
Методички
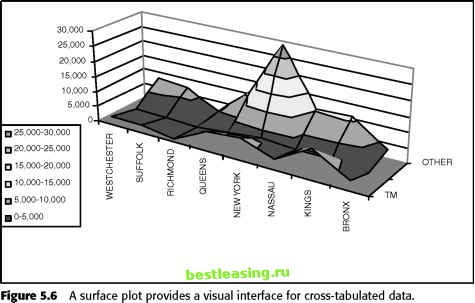
-5 -4 -3 -2 -1 0 1 2 3 4 5 Z-Value Figure 5.4 The tail of the normal distribution answers the question: What is the probability of getting a value of z or greater? Figure 5.5 shows the signed confidence for the data shown earlier in Figures 5.2 and 5.3, using the two-tailed probability. The shape of the signed confidence is different from the earlier shapes. The overall stops bounce around, usually remaining within reasonable bounds. The pricing-related stops, though, once again show a very distinct pattern, being too low for a long time, then peaking and descending. The signed confidence levels are bounded by 100 percent and -100 percent. In this chart, the extreme values are near 100 percent or -100 percent, and it is hard to tell the difference between 99.9 percent and 99.99999 percent. To distinguish values near the extremes, the z-values in Figure 5.3 are better than the signed confidence. 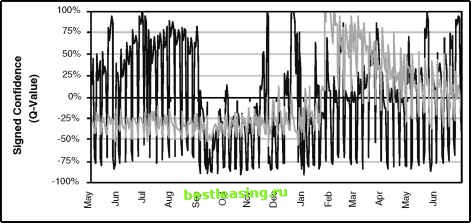 Figure 5.5 Based on the same data from Figures 5.2 and 5.3, this chart shows the signed confidence (q-values) of the observed value based on the average and standard deviation. This sign is positive when the observed value is too high, negative when it is too low. Cross-Tabulations Time series are an example of cross-tabulation-looking at the values of two or more variables at one time. For time series, the second variable is the time something occurred. Table 5.1 shows an example used later in this chapter. The cross-tabulation shows the number of new customers from counties in southeastern New York state by three channels: telemarketing, direct mail, and other. This table shows both the raw counts and the relative frequencies. It is possible to visualize cross-tabulations as well. However, there is a lot of data being presented, and some people do not follow complicated pictures. Figure 5.6 shows a surface plot for the counts shown in the table. A surface plot often looks a bit like hilly terrain. The counts are the height of the hills; the counties go up one side and the channels make the third dimension. This surface plot shows that the other channel is quite high for Manhattan (New York county). Although not a problem in this case, such peaks can hide other hills and valleys on the surface plot. Looking at Continuous Variables Statistics originated to understand the data collected by scientists, most of which took the form of continuous measurements. In data mining, we encounter continuous data less often, because there is a wealth of descriptive data as well. This section talks about continuous data from the perspective of descriptive statistics. Table 5.1 Cross-tabulation of Starts by County and Channel
 Statistical Measures for Continuous Variables The most basic statistical measures describe a set of data with just a single value. The most commonly used statistic is the mean or average value (the sum of all the values divided by the number of them). Some other important things to look at are: Range. The range is the difference between the smallest and largest observation in the sample. The range is often looked at along with the minimum and maximum values themselves. Mean. This is what is called an average in everyday speech. Median. The median value is the one which splits the observations into two equally sized groups, one having observations smaller than the median and another containing observations larger than the median. Mode. This is the value that occurs most often. The median can be used in some situations where it is impossible to calculate the mean, such as when incomes are reported in ranges of $10,000 dollars with a final category over $100,000. The number of observations are known in each group, but not the actual values. In addition, the median is less affected by a few observations that are out of line with the others. For instance, if Bill Gates moves onto your block, the average net worth of the neighborhood will dramatically increase. However, the median net worth may not change at all. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 [ 53 ] 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||