

|
|

|
Промышленный лизинг
Методички
statisticians use similar techniques to solve similar problems, the data mining approach differs from the standard statistical approach in several areas: Data miners tend to ignore measurement error in raw data. Data miners assume that there is more than enough data and processing power. Data mining assumes dependency on time everywhere. It can be hard to design experiments in the business world. Data is truncated and censored. These are differences of approach, rather than opposites. As such, they shed some light on how the business problems addressed by data miners differ from the scientific problems that spurred the development of statistics. No Measurement Error in Basic Data Statistics originally derived from measuring scientific quantities, such as the width of a skull or the brightness of a star. These measurements are quantitative and the precise measured value depends on factors such as the type of measuring device and the ambient temperature. In particular, two people taking the same measurement at the same time are going to produce slightly different results. The results might differ by 5 percent or 0.05 percent, but there is a difference. Traditionally, statistics looks at observed values as falling into a confidence interval. On the other hand, the amount of money a customer paid last January is quite well understood-down to the last penny. The definition of customer may be a little bit fuzzy; the definition of January may be fuzzy (consider 5-44 accounting cycles). However, the amount of the payment is precise. There is no measurement error. There are sources of error in business data. Of particular concern is operational error, which can cause systematic bias in what is being collected. For instance, clock skew may mean that two events that seem to happen in one sequence may happen in another. A database record may have a Tuesday update date, when it really was updated on Monday, because the updating process runs just after midnight. Such forms of bias are systematic, and potentially represent spurious patterns that might be picked up by data mining algorithms. One major difference between business data and scientific data is that the latter has many continuous values and the former has many discrete values. Even monetary amounts are discrete-two values can differ only by multiples of pennies (or some similar amount)-even though the values might be represented by real numbers. There Is a Lot of Data Traditionally, statistics has been applied to smallish data sets (at most a few thousand rows) with few columns (less than a dozen). The goal has been to squeeze as much information as possible out of the data. This is still important in problems where collecting data is expensive or arduous-such as market research, crash testing cars, or tests of the chemical composition of Martian soil. Business data, on the other hand, is very voluminous. The challenge is understanding anything about what is happening, rather than every possible thing. Fortunately, there is also enough computing power available to handle the large volumes of data. Sampling theory is an important part of statistics. This area explains how results on a subset of data (a sample) relate to the whole. This is very important when planning to do a poll, because it is not possible to ask everyone a question; rather, pollsters ask a very small sample and derive overall opinion. However, this is much less important when all the data is available. Usually, it is best to use all the data available, rather than a small subset of it. There are a few cases when this is not necessarily true. There might simply be too much data. Instead of building models on tens of millions of customers; build models on hundreds of thousands-at least to learn how to build better models. Another reason is to get an unrepresentative sample. Such a sample, for instance, might have an equal number of churners and nonchurners, although the original data had different proportions. However, it is generally better to use more data rather than sample down and use less, unless there is a good reason for sampling down. Time Dependency Pops Up Everywhere Almost all data used in data mining has a time dependency associated with it. Customers reactions to marketing efforts change over time. Prospects reactions to competitive offers change over time. Comparing results from a marketing campaign one year to the previous year is rarely going to yield exactly the same result. We do not expect the same results. On the other hand, we do expect scientific experiments to yield similar results regardless of when the experiment takes place. The laws of science are considered immutable; they do not change over time. By contrast, the business climate changes daily. Statistics often considers repeated observations to be independent observations. That is, one observation does not resemble another. Data mining, on the other hand, must often consider the time component of the data. Experimentation is Hard Data mining has to work within the constraints of existing business practices. This can make it difficult to set up experiments, for several reasons: Businesses may not be willing to invest in efforts that reduce short-term gain for long-term learning. Business processes may interfere with well-designed experimental methodologies. Factors that may affect the outcome of the experiment may not be obvious. Timing plays a critical role and may render results useless. Of these, the first two are the most difficult. The first simply says that tests do not get done. Or, they are done so poorly that the results are useless. The second poses the problem that a seemingly well-designed experiment may not be executed correctly. There are always hitches when planning a test; sometimes these hitches make it impossible to read the results. Data Is Censored and Truncated The data used for data mining is often incomplete, in one of two special ways. Censored values are incomplete because whatever is being measured is not complete. One example is customer tenures. For active customers, we know the tenure is greater than the current tenure; however, we do not know which customers are going to stop tomorrow and which are going to stop 10 years from now. The actual tenure is greater than the observed value and cannot be known until the customer actually stops at some unknown point in the future. 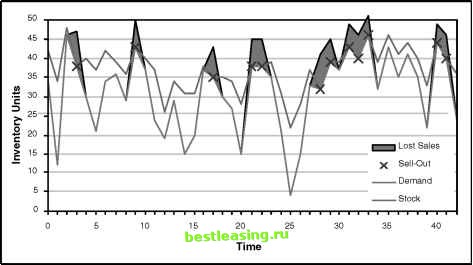 Figure 5.11 A time series of product sales and inventory illustrates the problem of censored data. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 [ 61 ] 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 |