

|
|

|
Промышленный лизинг
Методички
Picking the Best Subtree The next task is to select, from the pool of candidate subtrees, the one that works best on new data. That, of course, is the purpose of the validation set. Each of the candidate subtrees is used to classify the records in the validation set. The tree that performs this task with the lowest overall error rate is declared the winner. The winning subtree has been pruned sufficiently to remove the effects of overtraining, but not so much as to lose valuable information. The graph in Figure 6.7 illustrates the effect of pruning on classification accuracy. The technical aside goes into this in more detail. Because this pruning algorithm is based solely on misclassification rate, without taking the probability of each classification into account, it replaces any subtree whose leaves all make the same classification with a common parent that also makes that classification. In applications where the goal is to select a small proportion of the records (the top 1 percent or 10 percent, for example), this pruning algorithm may hurt the performance of the tree, since some of the removed leaves contain a very high proportion of the target class. Some tools, such as SAS Enterprise Miner, allow the user to prune trees optimally for such situations. Using the Test Set to Evaluate the Final Tree The winning subtree was selected on the basis of its overall error rate when applied to the task of classifying the records in the validation set. But, while we expect that the selected subtree will continue to be the best performing subtree when applied to other datasets, the error rate that caused it to be selected may slightly overstate its effectiveness. There are likely to be a large number of subtrees that all perform about as well as the one selected. To a certain extent, the one of these that delivered the lowest error rate on the validation set may simply have gotten lucky with that particular collection of records. For that reason, as explained in Chapter 3, the selected subtree is applied to a third preclassified dataset that is disjoint with both the validation set and the training set. This third dataset is called the test set. The error rate obtained on the test set is used to predict expected performance of the classification rules represented by the selected tree when applied to unclassified data. Wv7IililIiM Do not evaluate the performance of a model by its lift or error rate on the validation set. Like the training set, it has had a hand in creating the model and so will overstate the models accuracy. Always measure the models accuracy on a test set that is drawn from the same population as the training and validation sets, but has not been used in any way to create the model. 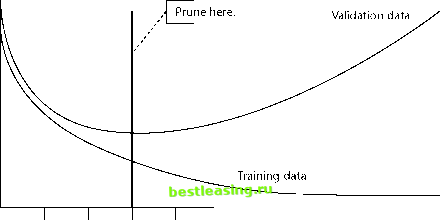 1 I I I I I Depth of Tree Figure 6.7 Pruning chooses the tree whose miscalculation rate is minimized on the validation set. The C5 Pruning Algorithm C5 is the most recent version of the decision-tree algorithm that Australian researcher, J. Ross Quinlan has been evolving and refining for many years. An earlier version, ID3, published in 1986, was very influential in the field of machine learning and its successors are used in several commercial data mining products. (The name ID3 stands for Iterative Dichotomiser 3. We have not heard an explanation for the name C5, but we can guess that Professor Quinlans background is mathematics rather than marketing.) C5 is available as a commercial product from RuleQuest (www.rulequest.com). The trees grown by C5 are similar to those grown by CART (although unlike CART, C5 makes multiway splits on categorical variables). Like CART, the C5 algorithm first grows an overfit tree and then prunes it back to create a more stable model. The pruning strategy is quite different, however. C5 does not make use of a validation set to choose from among candidate subtrees; the same data used to grow the tree is also used to decide how the tree should be pruned. This may reflect the algorithms origins in the academic world, where in the past, university researchers had a hard time getting their hands on substantial quantities of real data to use for training sets. Consequently, they spent much time and effort trying to coax the last few drops of information from their impoverished datasets-a problem that data miners in the business world do not face. Pessimistic Pruning C5 prunes the tree by examining the error rate at each node and assuming that the true error rate is actually substantially worse. If N records arrive at a node, and E of them are classified incorrectly, then the error rate at that node is E/N. Now the whole point of the tree-growing algorithm is to minimize this error rate, so the algorithm assumes that E/N is the best than can be done. C5 uses an analogy with statistical sampling to come up with an estimate of the worst error rate likely to be seen at a leaf. The analogy works by thinking of the data at the leaf as representing the results of a series of trials each of which can have one of two possible results. (Heads or tails is the usual example.) As it happens, statisticians have been studying this particular situation since at least 1713, the year that Jacques Bernoullis famous binomial formula was posthumously published. So there are well-known formulas for determining what it means to have observed E occurrences of some event in N trials. In particular, there is a formula which, for a given confidence level, gives the confidence interval-the range of expected values of E. C5 assumes that the observed number of errors on the training data is the low end of this range, and substitutes the high end to get a leafs predicted error rate, E/N on unseen data. The smaller the node, the higher the error rate. When the high-end estimate of the number of errors at a node is less than the estimate for the errors of its children, then the children are pruned. Stability-Based Pruning The pruning algorithms used by CART and C5 (and indeed by all the commercial decision tree tools that the authors have used) have a problem. They fail to prune some nodes that are clearly unstable. The split highlighted in Figure 6.8 is a good example. The picture was produced by SAS Enterprise 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 [ 71 ] 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 |