

|
|

|
Промышленный лизинг
Методички
Miner using its default settings for viewing a tree. The numbers on the left-hand side of each node show what is happening on the training set. The numbers on the right-hand side of each node show what is happening on the validation set. This particular tree is trying to identify churners. When only the training data is taken into consideration, the highlighted branch seems to do very well; the concentration of churners rises from 58.0 percent to 70.9 percent. Unfortunately, when the very same rule is applied to the validation set, the concentration of churners actually decreases from 56.6 percent to 52 percent. One of the main purposes of a model is to make consistent predictions on previously unseen records. Any rule that cannot achieve that goal should be eliminated from the model. Many data mining tools allow the user to prune a decision tree manually. This is a useful facility, but we look forward to data mining software that provides automatic stability-based pruning as an option. Such software would need to have a less subjective criterion for rejecting a split than the distribution of the validation set results looks different from the distribution of the training set results. One possibility would be to use a test of statistical significance, such as the chi-Square Test or the difference of proportions. The split would be pruned when the confidence level is less than some user-defined threshold, so only splits that are, say, 99 percent confident on the validation set would remain. 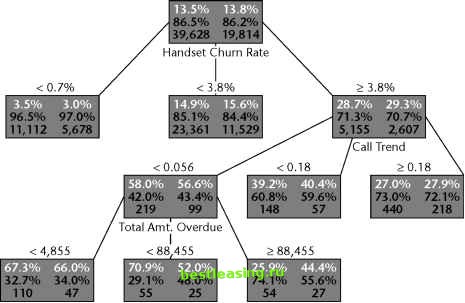 Figure 6.8 An unstable split produces very different distributions on the training and validation sets. Team-Fly® WARNING Small nodes cause big problems. A common cause of unstable decision tree models is allowing nodes with too few records. Most decision tree tools allow the user to set a minimum node size. As a rule of thumb, nodes that receive fewer than about 100 training set records are likely to be unstable. Extracting Rules from Trees When a decision tree is used primarily to generate scores, it is easy to forget that a decision tree is actually a collection of rules. If one of the purposes of the data mining effort is to gain understanding of the problem domain, it can be useful to reduce the huge tangle of rules in a decision tree to a smaller, more comprehensible collection. There are other situations where the desired output is a set of rules. In Mastering Data Mining, we describe the application of decision trees to an industrial process improvement problem, namely the prevention of a certain type of printing defect. In that case, the end product of the data mining project was a small collection of simple rules that could be posted on the wall next to each press. When a decision tree is used for producing scores, having a large number of leaves is advantageous because each leaf generates a different score. When the object is to generate rules, the fewer rules the better. Fortunately, it is often possible to collapse a complex tree into a smaller set of rules. The first step in that direction is to combine paths that lead to leaves that make the same classification. The partial decision tree in Figure 6.9 yields the following rules: Watch the game and home team wins and out with friends then beer. Watch the game and home team wins and sitting at home then diet soda. Watch the game and home team loses and out with friends then beer. Watch the game and home team loses and sitting at home then milk. The two rules that predict beer can be combined by eliminating the test for whether the home team wins or loses. That test is important for discriminating between milk and diet soda, but has no bearing on beer consumption. The new, simpler rule is: Watch the game and out with friends then beer. 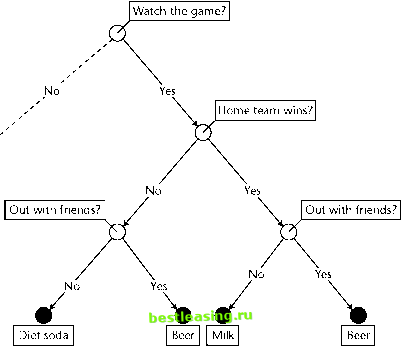 Figure 6.9 Multiple paths lead to the same conclusion. Up to this point, nothing is controversial because no information has been lost, but C5s rule generator goes farther. It attempts to generalize each rule by removing clauses, then comparing the predicted error rate of the new, briefer rule to that of the original using the same pessimistic error rate assumption used for pruning the tree in the first place. Often, the rules for several different leaves generalize to the same rule, so this process results in fewer rules than the decision tree had leaves. In the decision tree, every record ends up at exactly one leaf, so every record has a definitive classification. After the rule-generalization process, however, there may be rules that are not mutually exclusive and records that are not covered by any rule. Simply picking one rule when more than one is applicable can solve the first problem. The second problem requires the introduction of a default class assigned to any record not covered by any of the rules. Typically, the most frequently occurring class is chosen as the default. Once it has created a set of generalized rules, Quinlans C5 algorithm groups the rules for each class together and eliminates those that do not seem to contribute much to the accuracy of the set of rules as a whole. The end result is a small number of easy to understand rules. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 [ 72 ] 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 |