

|
|

|
Промышленный лизинг
Методички
The learning rate controls how quickly the weights change. The best approach for the learning rate is to start big and decrease it slowly as the network is being trained. Initially, the weights are random, so large oscillations are useful to get in the vicinity of the best weights. However, as the network gets closer to the optimal solution, the learning rate should decrease so the network can fine-tune to the most optimal weights. Researchers have invented hundreds of variations for training neural networks (see the sidebar Training As Optimization ). Each of these approaches has its advantages and disadvantages. In all cases, they are looking for a technique that trains networks quickly to arrive at an optimal solution. Some neural network packages offer multiple training methods, allowing users to experiment with the best solution for their problems. One of the dangers with any of the training techniques is falling into something called a local optimum. This happens when the network produces okay results for the training set and adjusting the weights no longer improves the performance of the network. However, there is some other combination of weights-significantly different from those in the network-that yields a much better solution. This is analogous to trying to climb to the top of a mountain by choosing the steepest path at every turn and finding that you have only climbed to the top of a nearby hill. There is a tension between finding the local best solution and the global best solution. Controlling the learning rate and momentum helps to find the best solution. Heuristics for Using Feed-Forward, Back Propagation Networks Even with sophisticated neural network packages, getting the best results from a neural network takes some effort. This section covers some heuristics for setting up a network to obtain good results. Probably the biggest decision is the number of units in the hidden layer. The more units, the more patterns the network can recognize. This would argue for a very large hidden layer. However, there is a drawback. The network might end up memorizing the training set instead of generalizing from it. In this case, more is not better. Fortunately, you can detect when a network is overtrained. If the network performs very well on the training set, but does much worse on the validation set, then this is an indication that it has memorized the training set. How large should the hidden layer be? The real answer is that no one knows. It depends on the data, the patterns being detected, and the type of network. Since overfitting is a major concern with networks using customer data, we generally do not use hidden layers larger than the number of inputs. A good place to start for many problems is to experiment with one, two, and three nodes in the hidden layer. This is feasible, especially since training neural networks now takes seconds or minutes, instead of hours. If adding more nodes improves the performance of the network, then larger may be better. When the network is overtraining, reduce the size of the layer. If it is not sufficiently accurate, increase its size. When using a network for classification, however, it can be useful to start with one hidden node for each class. Another decision is the size of the training set. The training set must be sufficiently large to cover the ranges of inputs available for each feature. In addition, you want several training examples for each weight in the network. For a network with s input units, h hidden units, and 1 output, there are h * (s + 1) + h + 1 weights in the network (each hidden layer node has a weight for each connection to the input layer, an additional weight for the bias, and then a connection to the output layer and its bias). For instance, if there are 15 input features and 10 units in the hidden network, then there are 171 weights in the network. There should be at least 30 examples for each weight, but a better minimum is 100. For this example, the training set should have at least 17,100 rows. Finally, the learning rate and momentum parameters are very important for getting good results out of a network using the back propagation training algorithm (it is better to use conjugate gradient or similar approach). Initially, the learning should be set high to make large adjustments to the weights. As the training proceeds, the learning rate should decrease in order to fine-tune the network. The momentum parameter allows the network to move toward a solution more rapidly, preventing oscillation around less useful weights. Choosing the Training Set The training set consists of records whose prediction or classification values are already known. Choosing a good training set is critical for all data mining modeling. A poor training set dooms the network, regardless of any other work that goes into creating it. Fortunately, there are only a few things to consider in choosing a good one. Coverage of Values for All Features The most important of these considerations is that the training set needs to cover the full range of values for all features that the network might encounter, including the output. In the real estate appraisal example, this means including inexpensive houses and expensive houses, big houses and little houses, and houses with and without garages. In general, it is a good idea to have several examples in the training set for each value of a categorical feature and for values throughout the ranges of ordered discrete and continuous features. Team-Fly® This is true regardless of whether the features are actually used as inputs into the network. For instance, lot size might not be chosen as an input variable in the network. However, the training set should still have examples from all different lot sizes. A network trained on smaller lot sizes (some of which might be low priced and some high priced) is probably not going to do a good job on mansions. Number of Features The number of input features affects neural networks in two ways. First, the more features used as inputs into the network, the larger the network needs to be, increasing the risk of overfitting and increasing the size of the training set. Second, the more features, the longer is takes the network to converge to a set of weights. And, with too many features, the weights are less likely to be optimal. This variable selection problem is a common problem for statisticians. In practice, we find that decision trees (discussed in Chapter 6) provide a good method for choosing the best variables. Figure 7.8 shows a nice feature of SAS Enterprise Miner. By connecting a neural network node to a decision tree node, the neural network only uses the variables chosen by the decision tree. An alternative method is to use intuition. Start with a handful of variables that make sense. Experiment by trying other variables to see which ones improve the model. In many cases, it is useful to calculate new variables that represent particular aspects of the business problem. In the real estate example, for instance, we might subtract the square footage of the house from the lot size to get an idea of how large the yard is. 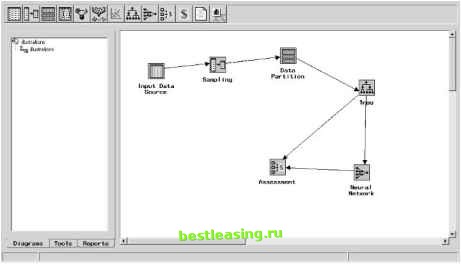 Figure 7.8 SAS Enterprise Miner provides a simple mechanism for choosing variables for a neural network-just connect a neural network node to a decision tree node. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 [ 85 ] 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 |