

|
|

|
Промышленный лизинг
Методички
Choosing the Number of Neighbors The investigation varied the number of nearest neighbors between 1 and 11 inclusive. The best results came from using more neighbors. However, this case study is different from many applications of MBR because it is assigning multiple categories to each story. The more typical problem is to assign only a single category or code and fewer neighbors would likely be sufficient for good results. The Results To measure the effectiveness of MBR on coding, the news service had a panel of editors review all the codes assigned, whether by editors or by MBR, to 200 stories. Only codes agreed upon by a majority of the panel were considered correct. The comparison of the correct codes to the codes originally assigned by human editors was interesting. Eighty-eight percent of the codes originally assigned to the stories (by humans) were correct. However, the human editors made mistakes. A total of 17 percent of the codes originally assigned by human editors were incorrect as shown in Figure 8.4. MBR did not do quite as well. For MBR, the corresponding percentages were 80 percent and 28 percent. That is, 80 percent of the codes assigned by MBR were correct, but the cost was that 28 percent of the codes assigned were incorrect. Codes assigned by panel of experts Incorrect codes in classification 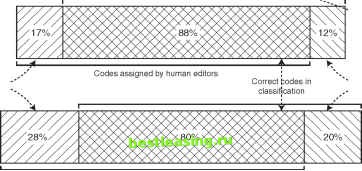 Correct codes not included in classification Codes assigned by MBR Figure 8.4 A comparison of results by human editors and by MBR on assigning codes to news stories. The mix of editors assigning the original codes, though, included novice, intermediate, and experienced editors. The MBR system actually performed as well as intermediate editors and better than novice editors. Also, MBR was using stories classified by the same mix of editors, so the training set was not consistently coded. Given the inconsistency in the training set, it is surprising that MBR did as well as it did. The study was not able to investigate using MBR on a training set whose codes were reviewed by the panel of experts because there were not enough such stories for a viable training set. This case study illustrates that MBR can be used for solving difficult problems that might not easily be solved by other means. Most data mining techniques cannot handle textual data and assigning multiple categories at the same time is problematic. This case study shows that, with some experimentation, MBR can produce results comparable to human experts. There is further discussion of the metrics used to evaluate the performance of a document classification or retrieval system in the sidebar entitled Measuring the Effectiveness of Assigning Codes. This study achieved these results with about two person-months of effort (not counting development of the relevance feedback engine). By comparison, other automated classification techniques, such as those based on expert systems, require many person-years of effort to achieve equivalent results for classifying news stories. Measuring Distance Say your travels are going to take you to a small town and you want to know the weather. If you have a newspaper that lists weather reports for major cities, what you would typically do is find the weather for cities near the small town. You might look at the closest city and just take its weather, or do some sort of combination of the forecasts for, say, the three closest cities. This is an example of using MBR to find the weather forecast. The distance function being used is the geographic distance between the two locations. It seems likely that the Web services that provide a weather forecast for any zip code supplied by a user do something similar. What Is a Distance Function? Distance is the way the MBR measures similarity. For any true distance metric, the distance from point A to point B, denoted by d(A,B), has four key properties: 1. Well-defined. The distance between two points is always defined and is a non-negative real number, d(A,B) > 0. 2. Identity. The distance from one point to itself is always zero, so d(A,A) = 0. 3. Commutativity. Direction does not make a difference, so the distance from A to B is the same as the distance from B to A: d(A,B) = d(B,A). This property precludes one-way roads, for instance. 4. Triangle Inequality. Visiting an intermediate point C on the way from A to B never shortens the distance, so d(A,B) > d(A,C) + d(C,B). For MBR, the points are really records in a database. This formal definition of distance is the basis for measuring similarity, but MBR still works pretty well when some of these constraints are relaxed a bit. For instance, the distance function in the news story classification case study was not commutative; that is, the distance from a news story A to another B was not always the same as the distance from B to A. However, the similarity measure was still useful for classification purposes. What makes these properties useful for MBR? The fact that distance is well-defined implies that every record has a neighbor somewhere in the database- and MBR needs neighbors in order to work. The identity property makes distance conform to the intuitive idea that the most similar record to a given record is the original record itself. Commutativity and the Triangle Inequality make the nearest neighbors local and well-behaved. Adding a new record into the database will not bring an existing record any closer. Similarity is a matter reserved for just two records at a time. Although the distance measure used to find nearest neighbors is well-behaved, the set of nearest neighbors can have some peculiar properties. For instance, the nearest neighbor to a record B may be A, but A may have many neighbors closer than B, as shown in Figure 8.5. This situation does not pose problems for MBR. Bs nearest neighbor is A. X X X X / A* All these neighbors of xx A are closer than B. x Figure 8.5 Bs nearest neighbor is A, but A has many neighbors closer than B. Team-Fly® 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 [ 98 ] 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 |